提示工程模式
基于全面的 提示工程指南 的提示工程技术实际实现。 该指南涵盖了有效提示工程的理论、原则和模式,而在这里,我们将演示如何使用 Spring AI 流畅的 ChatClient API 将这些概念转化为可运行的 Java 代码。 本文中使用的演示源代码可在以下位置获取:提示工程模式示例。
1. 配置
配置部分概述了如何使用 Spring AI 设置和调整您的大型语言模型 (LLM)。 它涵盖了为您的用例选择合适的 LLM 提供商,以及配置控制模型输出质量、风格和格式的重要生成参数。
LLM 提供商选择
对于提示工程,您将首先选择一个模型。
Spring AI 支持 多个 LLM 提供商(例如 OpenAI、Anthropic、Google Vertex AI、AWS Bedrock、Ollama 等),让您无需更改应用程序代码即可切换提供商——只需更新您的配置。
只需添加选定的 starter 依赖项 spring-ai-starter-model-<MODEL-PROVIDER-NAME>。
例如,以下是启用 Anthropic Claude API 的方法:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-anthropic</artifactId>
</dependency>您可以像这样指定 LLM 模型名称:
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest") // 使用 Anthropic 的 Claude 模型
.build())有关启用每个模型的详细信息,请参阅 参考文档。
LLM 输出配置
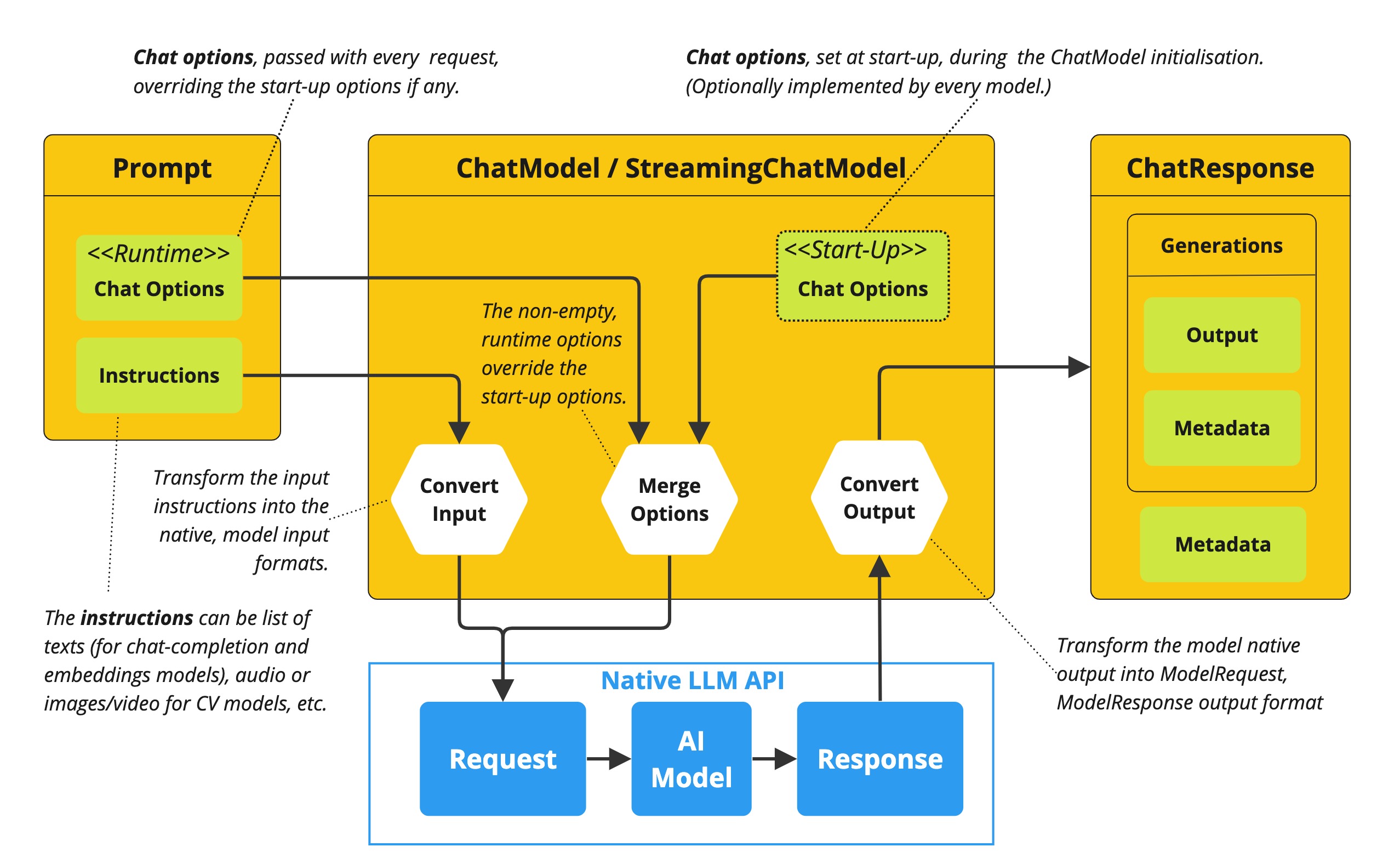
在我们深入探讨提示工程技术之前,了解如何配置 LLM 的输出行为至关重要。Spring AI 提供了多种配置选项,您可以通过 ChatOptions 构建器控制生成的各个方面。
所有配置都可以通过编程方式应用,如下面的示例所示,也可以在启动时通过 Spring 应用程序属性应用。
温度
温度控制模型响应的随机性或“创造性”。
-
较低值 (0.0-0.3):更具确定性、更集中的响应。更适合事实性问题、分类或一致性至关重要的任务。
-
中等值 (0.4-0.7):在确定性和创造性之间取得平衡。适用于一般用例。
-
较高值 (0.8-1.0):更具创造性、多样化且可能出人意料的响应。更适合创意写作、头脑风暴或生成多样化选项。
.options(ChatOptions.builder()
.temperature(0.1) // 非常确定性的输出
.build())理解温度对于提示工程至关重要,因为不同的技术受益于不同的温度设置。
输出长度 (MaxTokens)
maxTokens 参数限制模型在其响应中可以生成的 token(词块)数量。
-
低值 (5-25):用于单个单词、短语或分类标签。
-
中等值 (50-500):用于段落或简短解释。
-
高值 (1000+):用于长篇内容、故事或复杂解释。
.options(ChatOptions.builder()
.maxTokens(250) // 中等长度响应
.build())设置适当的输出长度对于确保您获得完整响应而没有不必要的冗长非常重要。
采样控制 (Top-K 和 Top-P)
这些参数使您可以精细控制生成过程中的 token 选择。
-
Top-K:将 token 选择限制为 K 个最有可能的下一个 token。较高的值(例如,40-50)会引入更多多样性。
-
Top-P(核采样):从累积概率超过 P 的最小 token 集中动态选择。0.8-0.95 这样的值很常见。
.options(ChatOptions.builder()
.topK(40) // 仅考虑前 40 个 token
.topP(0.8) // 从覆盖 80% 概率质量的 token 中采样
.build())这些采样控制与温度协同工作,以塑造响应特性。
结构化响应格式
除了纯文本响应(使用 .content())之外,Spring AI 还使用 .entity() 方法,可以轻松地将 LLM 响应直接映射到 Java 对象。
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
Sentiment result = chatClient.prompt("...")
.call()
.entity(Sentiment.class);此功能与指示模型返回结构化数据的系统提示结合使用时尤其强大。
模型特定选项
虽然可移植的 ChatOptions 在不同的 LLM 提供商之间提供了一致的接口,但 Spring AI 还提供了模型特定的选项类,用于公开提供商特定的功能和配置。这些模型特定的选项允许您利用每个 LLM 提供商的独特功能。
// 使用 OpenAI 特定选项
OpenAiChatOptions openAiOptions = OpenAiChatOptions.builder()
.model("gpt-4o")
.temperature(0.2)
.frequencyPenalty(0.5) // OpenAI 特定参数
.presencePenalty(0.3) // OpenAI 特定参数
.responseFormat(new ResponseFormat("json_object")) // OpenAI 特定 JSON 模式
.seed(42) // OpenAI 特定确定性生成
.build();
String result = chatClient.prompt("...")
.options(openAiOptions)
.call()
.content();
// 使用 Anthropic 特定选项
AnthropicChatOptions anthropicOptions = AnthropicChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.2)
.topK(40) // Anthropic 特定参数
.thinking(AnthropicApi.ThinkingType.ENABLED, 1000) // Anthropic 特定思考配置
.build();
String result = chatClient.prompt("...")
.options(anthropicOptions)
.call()
.content();每个模型提供商都有自己的聊天选项实现(例如 OpenAiChatOptions、AnthropicChatOptions、MistralAiChatOptions),这些实现公开了提供商特定的参数,同时仍然实现了通用接口。这种方法为您提供了灵活性,可以使用可移植选项以实现跨提供商兼容性,或者在需要访问特定提供商的独特功能时使用模型特定选项。
请注意,当使用模型特定选项时,您的代码将与该特定提供商绑定,从而降低可移植性。这是在访问高级提供商特定功能与在应用程序中保持提供商独立性之间的一种权衡。
2. 提示工程技术
以下每个部分都实现了指南中的特定提示工程技术。 通过遵循“提示工程”指南和这些实现,您将对可用的提示工程技术以及如何在生产 Java 应用程序中有效地实现它们有透彻的理解。
2.1 零样本提示
零样本提示涉及要求 AI 执行任务而不提供任何示例。这种方法测试模型从头开始理解和执行指令的能力。大型语言模型在大量的文本语料库上进行训练,使它们能够理解“翻译”、“摘要”或“分类”等任务的含义,而无需明确的演示。
零样本非常适合模型可能在训练期间看到过类似示例的简单任务,以及您希望最小化提示长度的情况。但是,性能可能因任务复杂性和指令的制定方式而异。
// 第 2.1 节实现:通用提示/零样本(第 15 页)
public void pt_zero_shot(ChatClient chatClient) {
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
Sentiment reviewSentiment = chatClient.prompt("""
将电影评论分类为正面、中性或负面。
评论:《她》是一部令人不安的研究,揭示了如果人工智能被允许 unchecked 地继续发展,
人类将走向何方。我希望有更多像这部杰作一样的电影。
情感:
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.1)
.maxTokens(5)
.build())
.call()
.entity(Sentiment.class);
System.out.println("输出: " + reviewSentiment);
}此示例展示了如何在不提供示例的情况下对电影评论情感进行分类。请注意较低的温度 (0.1) 以获得更确定的结果,以及直接 .entity(Sentiment.class) 映射到 Java 枚举。
参考: Brown, T. B., et al. (2020)。“语言模型是少样本学习器。” arXiv:2005.14165。https://arxiv.org/abs/2005.14165
2.2 单样本和少样本提示
少样本提示为模型提供一个或多个示例,以帮助指导其响应,这对于需要特定输出格式的任务尤其有用。通过向模型展示所需输入-输出对的示例,它可以学习模式并将其应用于新输入,而无需显式参数更新。
单样本提供一个示例,当示例成本高昂或模式相对简单时,这很有用。少样本使用多个示例(通常是 3-5 个)来帮助模型更好地理解更复杂任务中的模式或说明正确输出的不同变体。
// 第 2.2 节实现:单样本和少样本(第 16 页)
public void pt_one_shot_few_shots(ChatClient chatClient) {
String pizzaOrder = chatClient.prompt("""
将顾客的披萨订单解析为有效的 JSON
示例 1:
我想要一个带奶酪、番茄酱和意大利辣香肠的小披萨。
JSON 响应:
```
{
"size": "small",
"type": "normal",
"ingredients": ["cheese", "tomato sauce", "pepperoni"]
}
```
示例 2:
我能要一个带番茄酱、罗勒和马苏里拉奶酪的大披萨吗?
JSON 响应:
```
{
"size": "large",
"type": "normal",
"ingredients": ["tomato sauce", "basil", "mozzarella"]
}
```
现在,我想要一个大披萨,一半是奶酪和马苏里拉奶酪。
另一半是番茄酱、火腿和菠萝。
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.1)
.maxTokens(250)
.build())
.call()
.content();
}少样本提示对于需要特定格式、处理边缘情况或任务定义在没有示例的情况下可能模糊的任务特别有效。示例的质量和多样性显著影响性能。
参考: Brown, T. B., et al. (2020)。“语言模型是少样本学习器。” arXiv:2005.14165。https://arxiv.org/abs/2005.14165
2.3 系统、上下文和角色提示
系统提示
系统提示为语言模型设置了整体上下文和目的,定义了模型应该做什么的“大局”。它建立了模型响应的行为框架、约束和高级目标,与特定的用户查询分开。
系统提示在整个对话中充当持久的“使命宣言”,允许您设置全局参数,例如输出格式、语气、道德界限或角色定义。与侧重于特定任务的用户提示不同,系统提示框定了所有用户提示应如何解释。
// 第 2.3.1 节实现:系统提示
public void pt_system_prompting_1(ChatClient chatClient) {
String movieReview = chatClient
.prompt()
.system("将电影评论分类为正面、中性或负面。只返回大写标签。")
.user("""
评论:《她》是一部令人不安的研究,揭示了如果人工智能被允许 unchecked 地继续发展,
人类将走向何方。它太令人不安了,我无法看完。
情感:
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(1.0)
.topK(40)
.topP(0.8)
.maxTokens(5)
.build())
.call()
.content();
}系统提示与 Spring AI 的实体映射功能结合使用时尤其强大:
// 第 2.3.1 节实现:带有 JSON 输出的系统提示
record MovieReviews(Movie[] movie_reviews) {
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
record Movie(Sentiment sentiment, String name) {
}
}
MovieReviews movieReviews = chatClient
.prompt()
.system("""
将电影评论分类为正面、中性或负面。返回
有效的 JSON。
""")
.user("""
评论:《她》是一部令人不安的研究,揭示了如果人工智能被允许 unchecked 地继续发展,
人类将走向何方。它太令人不安了,我无法看完。
JSON 响应:
""")
.call()
.entity(MovieReviews.class);系统提示对于多轮对话特别有价值,可确保跨多个查询的一致行为,并用于建立应适用于所有响应的格式约束,例如 JSON 输出。
参考: OpenAI。(2022)。“系统消息。” https://platform.openai.com/docs/guides/chat/introduction
角色提示
角色提示指示模型采用特定的角色或人物,这会影响其内容生成方式。通过为模型分配特定的身份、专业知识或视角,您可以影响其响应的风格、语气、深度和框架。
角色提示利用了模型模拟不同专业领域和沟通风格的能力。常见的角色包括专家(例如,“您是一位经验丰富的数据科学家”)、专业人士(例如,“充当旅行指南”)或风格化角色(例如,“像莎士比亚一样解释”)。
// 第 2.3.2 节实现:角色提示
public void pt_role_prompting_1(ChatClient chatClient) {
String travelSuggestions = chatClient
.prompt()
.system("""
我希望您扮演一名旅行指南。我将向您介绍我的位置,您将建议我附近 3 个值得参观的地方。
在某些情况下,我还会告诉您我将参观的地方类型。
""")
.user("""
我的建议:“我在阿姆斯特丹,我只想参观博物馆。”
旅行建议:
""")
.call()
.content();
}角色提示可以通过风格指令进行增强:
// 第 2.3.2 节实现:带有风格指令的角色提示
public void pt_role_prompting_2(ChatClient chatClient) {
String humorousTravelSuggestions = chatClient
.prompt()
.system("""
我希望您扮演一名旅行指南。我将向您介绍我的位置,您将以幽默的风格建议我附近 3 个值得参观的地方。
""")
.user("""
我的建议:“我在阿姆斯特丹,我只想参观博物馆。”
旅行建议:
""")
.call()
.content();
}这种技术对于专业领域知识、在响应中实现一致的语气以及创建更具吸引力、个性化的用户交互尤其有效。
参考: Shanahan, M., et al. (2023)。“与大型语言模型进行角色扮演。” arXiv:2305.16367。https://arxiv.org/abs/2305.16367
上下文提示
上下文提示通过传递上下文参数为模型提供额外的背景信息。这种技术丰富了模型对特定情况的理解,从而能够提供更相关和量身定制的响应,而不会使主要指令混乱。
通过提供上下文信息,您可以帮助模型理解与当前查询相关的特定领域、受众、约束或背景事实。这会带来更准确、相关且框架适当的响应。
// 第 2.3.3 节实现:上下文提示
public void pt_contextual_prompting(ChatClient chatClient) {
String articleSuggestions = chatClient
.prompt()
.user(u -> u.text("""
建议 3 个文章主题,并简要描述文章应包含的内容。
上下文:{context}
""")
.param("context", "您正在为一篇关于 80 年代复古街机视频游戏的博客撰写文章。"))
.call()
.content();
}Spring AI 使用 param() 方法注入上下文变量,使上下文提示变得清晰。当模型需要特定领域知识、将响应适应特定受众或场景以及确保响应符合特定约束或要求时,这种技术尤其有价值。
参考: Liu, P., et al. (2021)。“什么使 GPT-3 的上下文示例更好?” arXiv:2101.06804。https://arxiv.org/abs/2101.06804
2.4 回溯提示
回溯提示通过首先获取背景知识将复杂的请求分解为更简单的步骤。这种技术鼓励模型首先“回溯”到更广泛的上下文、基本原理或与问题相关的通用知识,然后再解决特定查询。
通过将复杂问题分解为更易于管理的组件并首先建立基础知识,模型可以为难题提供更准确的响应。
// 第 2.4 节实现:回溯提示
public void pt_step_back_prompting(ChatClient.Builder chatClientBuilder) {
// 设置聊天客户端的通用选项
var chatClient = chatClientBuilder
.defaultOptions(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(1.0)
.topK(40)
.topP(0.8)
.maxTokens(1024)
.build())
.build();
// 首先获取高级概念
String stepBack = chatClient
.prompt("""
基于流行的第一人称射击动作游戏,5 个虚构的关键设定是什么,它们有助于第一人称射击视频游戏中具有挑战性和引人入胜的关卡故事情节?
""")
.call()
.content();
// 然后在主任务中使用这些概念
String story = chatClient
.prompt()
.user(u -> u.text("""
为第一人称射击视频游戏的新关卡编写一段故事情节,该情节具有挑战性和引人入胜。
上下文:{step-back}
""")
.param("step-back", stepBack))
.call()
.content();
}回溯提示对于复杂的推理任务、需要专业领域知识的问题以及当您想要更全面和深思熟虑的响应而不是即时答案时特别有效。
参考: Zheng, Z., et al. (2023)。“退一步:通过抽象唤起大型语言模型中的推理。” arXiv:2310.06117。https://arxiv.org/abs/2310.06117
2.5 思维链 (CoT)
思维链提示鼓励模型逐步推理问题,从而提高复杂推理任务的准确性。通过明确要求模型展示其工作或以逻辑步骤思考问题,您可以显著提高多步推理任务的性能。
CoT 通过鼓励模型在生成最终答案之前生成中间推理步骤来工作,类似于人类解决复杂问题的方式。这使得模型的思维过程变得明确,并帮助它得出更准确的结论。
// 第 2.5 节实现:思维链 (CoT) - 零样本方法
public void pt_chain_of_thought_zero_shot(ChatClient chatClient) {
String output = chatClient
.prompt("""
我 3 岁时,我的伴侣是我的 3 倍。现在我 20 岁了。我的伴侣多大了?
让我们一步一步地思考。
""")
.call()
.content();
}
// 第 2.5 节实现:思维链 (CoT) - 少样本方法
public void pt_chain_of_thought_singleshot_fewshots(ChatClient chatClient) {
String output = chatClient
.prompt("""
问:我哥哥 2 岁时,我是他的两倍大。现在我 40 岁了。我哥哥多大了?让我们一步一步地思考。
答:我哥哥 2 岁时,我是 2 * 2 = 4 岁。
年龄差是 2 岁,我比他大。现在我 40 岁了,所以我哥哥是 40 - 2 = 38 岁。答案是 38。
问:我 3 岁时,我的伴侣是我的 3 倍大。现在我 20 岁了。我的伴侣多大了?让我们一步一步地思考。
答:
""")
.call()
.content();
}关键短语“让我们一步一步地思考”触发模型显示其推理过程。CoT 对于数学问题、逻辑推理任务以及任何需要多步推理的问题特别有价值。它通过使中间推理明确化来帮助减少错误。
参考: Wei, J., et al. (2022)。“思维链提示引发大型语言模型中的推理。” arXiv:2201.11903。https://arxiv.org/abs/2201.11903
2.6 自洽性
自洽性涉及多次运行模型并聚合结果以获得更可靠的答案。这种技术通过对相同问题采样不同的推理路径并通过多数投票选择最一致的答案来解决 LLM 输出中的可变性。
通过以不同的温度或采样设置生成多个推理路径,然后聚合最终答案,自洽性提高了复杂推理任务的准确性。它本质上是 LLM 输出的一种集成方法。
// 第 2.6 节实现:自洽性
public void pt_self_consistency(ChatClient chatClient) {
String email = """
嗨,
我看到您使用 Wordpress 搭建您的网站。一个很棒的开源内容管理系统。我过去也用过它。它附带了许多很棒的用户插件。而且设置起来非常容易。
我确实注意到联系表单中有一个 bug,当您选择姓名字段时会发生。请参阅我输入姓名字段文本的附带屏幕截图。请注意我调用的 JavaScript 警报框。
但除此之外,这是一个很棒的网站。我很喜欢阅读它。请随意将 bug 留在网站中,因为它给了我更多有趣的东西可读。
此致,
黑客哈利。
""";
record EmailClassification(Classification classification, String reasoning) {
enum Classification {
IMPORTANT, NOT_IMPORTANT
}
}
int importantCount = 0;
int notImportantCount = 0;
// 使用相同的输入运行模型 5 次
for (int i = 0; i < 5; i++) {
EmailClassification output = chatClient
.prompt()
.user(u -> u.text("""
电子邮件:{email}
将上述电子邮件分类为重要或不重要。让我们
一步一步地思考并解释原因。
""")
.param("email", email))
.options(ChatOptions.builder()
.temperature(1.0) // 较高的温度以获得更多变体
.build())
.call()
.entity(EmailClassification.class);
// 统计结果
if (output.classification() == EmailClassification.Classification.IMPORTANT) {
importantCount++;
} else {
notImportantCount++;
}
}
// 通过多数投票确定最终分类
String finalClassification = importantCount > notImportantCount ?
"重要" : "不重要";
}自洽性对于高风险决策、复杂推理任务以及当您需要比单个响应更能确信的答案时特别有价值。权衡是由于多次 API 调用而增加的计算成本和延迟。
参考: Wang, X., et al. (2022)。“自洽性改善了语言模型中的思维链推理。” arXiv:2203.11171。https://arxiv.org/abs/2203.11171
2.7 思维树 (ToT)
思维树 (ToT) 是一种高级推理框架,通过同时探索多个推理路径来扩展思维链。它将问题解决视为一个搜索过程,模型在此过程中生成不同的中间步骤,评估它们的潜力,并探索最有前途的路径。
这种技术对于具有多种可能方法或解决方案需要探索各种替代方案才能找到最佳路径的复杂问题特别强大。
|
原始的“提示工程”指南没有提供 ToT 的实现示例,这很可能是由于其复杂性。下面是一个简化示例,演示了核心概念。 |
游戏解决 ToT 示例:
// 第 2.7 节实现:思维树 (ToT) - 游戏解决示例
public void pt_tree_of_thoughts_game(ChatClient chatClient) {
// 步骤 1:生成多个初始棋步
String initialMoves = chatClient
.prompt("""
您正在玩国际象棋。棋盘处于起始位置。
生成 3 种不同的可能开局棋步。对于每一步:
1. 用代数记谱法描述棋步
2. 解释此棋步背后的战略思想
3. 评估棋步的强度(1-10 分)
""")
.options(ChatOptions.builder()
.temperature(0.7)
.build())
.call()
.content();
// 步骤 2:评估并选择最有前途的棋步
String bestMove = chatClient
.prompt()
.user(u -> u.text("""
分析这些开局棋步并选择最强的一个:
{moves}
一步一步解释您的推理,考虑:
1. 位置控制
2. 发展潜力
3. 长期战略优势
然后选择唯一的最佳棋步。
""").param("moves", initialMoves))
.call()
.content();
// 步骤 3:从最佳棋步探索未来的游戏状态
String gameProjection = chatClient
.prompt()
.user(u -> u.text("""
基于此选定的开局棋步:
{best_move}
预测双方接下来 3 步棋。对于每个潜在分支:
1. 描述棋步和反棋步
2. 评估由此产生的位置
3. 确定最有前途的延续
最后,确定最有利的棋步序列。
""").param("best_move", bestMove))
.call()
.content();
}参考: Yao, S., et al. (2023)。“思维树:使用大型语言模型进行深思熟虑的问题解决。” arXiv:2305.10601。https://arxiv.org/abs/2305.10601
2.8 自动提示工程
自动提示工程使用 AI 生成和评估替代提示。这种元技术利用语言模型本身来创建、完善和基准测试不同的提示变体,以找到特定任务的最佳公式。
通过系统地生成和评估提示变体,APE 可以找到比手动工程更有效的提示,特别是对于复杂任务。这是一种利用 AI 提高自身性能的方法。
// 第 2.8 节实现:自动提示工程
public void pt_automatic_prompt_engineering(ChatClient chatClient) {
// 生成相同请求的变体
String orderVariants = chatClient
.prompt("""
我们有一个乐队周边 T 恤网店,为了训练聊天机器人,我们需要各种订购方式:“一件 Metallica T 恤 S 码”。生成 10 个变体,语义相同但保持相同的含义。
""")
.options(ChatOptions.builder()
.temperature(1.0) // 高温以增强创造力
.build())
.call()
.content();
// 评估并选择最佳变体
String output = chatClient
.prompt()
.user(u -> u.text("""
请对以下变体执行 BLEU(双语评估替补)评估:
----
{variants}
----
选择评估分数最高的指令候选。
""").param("variants", orderVariants))
.call()
.content();
}APE 对于优化生产系统的提示、解决手动提示工程已达到极限的挑战性任务以及系统地大规模提高提示质量特别有价值。
参考: Zhou, Y., et al. (2022)。“大型语言模型是人类水平的提示工程师。” arXiv:2211.01910。https://arxiv.org/abs/2211.01910
2.9 代码提示
代码提示是指用于代码相关任务的专用技术。这些技术利用 LLM 理解和生成编程语言的能力,使它们能够编写新代码、解释现有代码、调试问题以及在语言之间进行翻译。
有效的代码提示通常涉及清晰的规范、适当的上下文(库、框架、样式指南),有时还包括类似代码的示例。温度设置通常较低(0.1-0.3),以获得更确定的输出。
// 第 2.9.1 节实现:用于编写代码的提示
public void pt_code_prompting_writing_code(ChatClient chatClient) {
String bashScript = chatClient
.prompt("""
用 Bash 编写一个代码片段,它要求输入一个文件夹名称。
然后它获取文件夹的内容并通过在文件名前面加上“draft”来重命名其中的所有文件。
""")
.options(ChatOptions.builder()
.temperature(0.1) // 低温以获得确定性代码
.build())
.call()
.content();
}
// 第 2.9.2 节实现:用于解释代码的提示
public void pt_code_prompting_explaining_code(ChatClient chatClient) {
String code = """
#!/bin/bash
echo "输入文件夹名称: "
read folder_name
if [ ! -d "$folder_name" ]; then
echo "文件夹不存在。"
exit 1
fi
files=( "$folder_name"/* )
for file in "${files[@]}"; do
new_file_name="draft_$(basename "$file")"
mv "$file" "$new_file_name"
done
echo "文件重命名成功。"
""";
String explanation = chatClient
.prompt()
.user(u -> u.text("""
向我解释以下 Bash 代码:
```
{code}
```
""").param("code", code))
.call()
.content();
}
// 第 2.9.3 节实现:用于翻译代码的提示
public void pt_code_prompting_translating_code(ChatClient chatClient) {
String bashCode = """
#!/bin/bash
echo "输入文件夹名称: "
read folder_name
if [ ! -d "$folder_name" ]; then
echo "文件夹不存在。"
exit 1
fi
files=( "$folder_name"/* )
for file in "${files[@]}"; do
new_file_name="draft_$(basename "$file")"
mv "$file" "$new_file_name"
done
echo "文件重命名成功。"
""";
String pythonCode = chatClient
.prompt()
.user(u -> u.text("""
将以下 Bash 代码翻译成 Python 代码片段:
{code}
""").param("code", bashCode))
.call()
.content();
}代码提示对于自动化代码文档、原型设计、学习编程概念以及在编程语言之间进行翻译特别有价值。通过将其与少样本提示或思维链等技术结合使用,可以进一步提高其有效性。
参考: Chen, M., et al. (2021)。“评估在代码上训练的大型语言模型。” arXiv:2107.03374。https://arxiv.org/abs/2107.03374
结论
Spring AI 提供了一个优雅的 Java API,用于实现所有主要的提示工程技术。通过将这些技术与 Spring 强大的实体映射和流畅的 API 相结合,开发人员可以使用清晰、可维护的代码构建复杂的 AI 驱动应用程序。
最有效的方法通常涉及结合多种技术——例如,将系统提示与少样本示例结合使用,或者将思维链与角色提示结合使用。Spring AI 灵活的 API 使这些组合易于实现。
对于生产应用程序,请记住:
-
使用不同的参数(温度、top-k、top-p)测试提示
-
考虑将自洽性用于关键决策
-
利用 Spring AI 的实体映射实现类型安全的响应
-
使用上下文提示提供应用程序特定的知识
通过这些技术和 Spring AI 强大的抽象,您可以创建健壮的 AI 驱动应用程序,提供一致、高质量的结果。
参考
-
Brown, T. B., et al. (2020)。“语言模型是少样本学习器。” arXiv:2005.14165。
-
Wei, J., et al. (2022)。“思维链提示引发大型语言模型中的推理。” arXiv:2201.11903。
-
Wang, X., et al. (2022)。“自洽性改善了语言模型中的思维链推理。” arXiv:2203.11171。
-
Yao, S., et al. (2023)。“思维树:使用大型语言模型进行深思熟虑的问题解决。” arXiv:2305.10601。
-
Zhou, Y., et al. (2022)。“大型语言模型是人类水平的提示工程师。” arXiv:2211.01910。
-
Zheng, Z., et al. (2023)。“退一步:通过抽象唤起大型语言模型中的推理。” arXiv:2310.06117。
-
Liu, P., et al. (2021)。“什么使 GPT-3 的上下文示例更好?” arXiv:2101.06804。
-
Shanahan, M., et al. (2023)。“与大型语言模型进行角色扮演。” arXiv:2305.16367。
-
Chen, M., et al. (2021)。“评估在代码上训练的大型语言模型。” arXiv:2107.03374。