Custom queries
与所有其他 Spring Data 模块一样,Spring Data Neo4j 允许你在存储库中指定自定义查询。如果你无法通过派生查询函数来表达查找器逻辑,那么这些会派上用场。 因为 Spring Data Neo4j 主要在底层工作上以记录为导向,所以记住这一点并不要为同一个“根节点”构建一个包含多个记录的结果集非常重要。
|
请在常见问题解答中了解如何使用来自存储库的自定义查询的替代形式,特别是如何将自定义查询与自定义映射结合使用:Custom queries and custom mappings。 |
Queries with relationships
Beware of the cartesian product
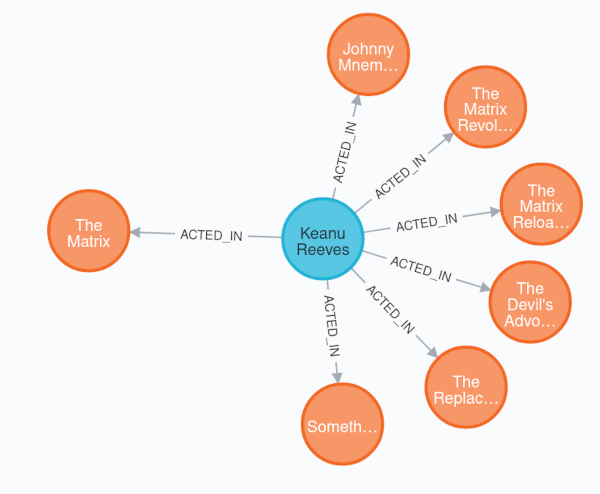
假设您有一个像 MATCH (m:Movie{title: 'The Matrix'})←[r:ACTED_IN]-(p:Person) return m,r,p 这样的查询,结果是这样的:
+------------------------------------------------------------------------------------------+
| m | r | p |
+------------------------------------------------------------------------------------------+
| (:Movie) | [:ACTED_IN {roles: ["Emil"]}] | (:Person {name: "Emil Eifrem"}) |
| (:Movie) | [:ACTED_IN {roles: ["Agent Smith"]}] | (:Person {name: "Hugo Weaving}) |
| (:Movie) | [:ACTED_IN {roles: ["Morpheus"]}] | (:Person {name: "Laurence Fishburne"}) |
| (:Movie) | [:ACTED_IN {roles: ["Trinity"]}] | (:Person {name: "Carrie-Anne Moss"}) |
| (:Movie) | [:ACTED_IN {roles: ["Neo"]}] | (:Person {name: "Keanu Reeves"}) |
+------------------------------------------------------------------------------------------+
映射的结果很可能无法使用。如果将其映射到列表中,它将包含 Movie 的重复项,但这部电影只会有一种关系。
Getting one record per root node
要返回正确对象,需要在查询中 collect 关系和相关节点: MATCH (m:Movie{title: 'The Matrix'})←[r:ACTED_IN]-(p:Person) return m,collect(r),collect(p)
+------------------------------------------------------------------------+ | m | collect(r) | collect(p) | +------------------------------------------------------------------------+ | (:Movie) | [[:ACTED_IN], [:ACTED_IN], ...]| [(:Person), (:Person),...] | +------------------------------------------------------------------------+
通过这样的结果作为单条记录,Spring Data Neo4j 才有可能将所有相关节点正确添加到根节点。
Reaching deeper into the graph
上述示例假设你只尝试提取相关节点的第一级。这有时是不够的,图中可能还有更多的节点,这些节点也应该成为映射实例的一部分。有两种方法可以实现此目的:数据库端还原或客户端端还原。
为此,上述示例还应该在 Movie 初始返回的 Persons 上包含 Movies。
Database-side reduction
记住 Spring Data Neo4j 只能正确处理基于记录的,一个实体实例的结果需要在一份记录中。使用 Cypher’s path 功能是获取图中所有分支的有效选项。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN p;这会产生多个路径,这些路径不会在一条记录中合并。可以调用 collect(p),但是 Spring Data Neo4j 不理解映射过程中路径的概念。因此,需要为结果提取节点和关系。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN m, nodes(p), relationships(p);由于有多条路径从《黑客帝国》通往其他电影,因此结果仍然不是单条记录。此时, Cypher’s reduce function 便发挥了作用。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
WITH collect(p) as paths, m
WITH m,
reduce(a=[], node in reduce(b=[], c in [aa in paths | nodes(aa)] | b + c) | case when node in a then a else a + node end) as nodes,
reduce(d=[], relationship in reduce(e=[], f in [dd in paths | relationships(dd)] | e + f) | case when relationship in d then d else d + relationship end) as relationships
RETURN m, relationships, nodes;reduce 函数允许我们展平不同路径中的节点和关系。结果,我们将获得类似于 Getting one record per root node 的元组,但集合中混合了关系类型或节点。
Client-side reduction
如果应在客户端发生规约,Spring Data Neo4j 可以让你还能映射关系或节点的列表列表。尽管如此,仍然要求返回的记录应包含所有信息,以便正确填充结果实体实例。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN m, collect(nodes(p)), collect(relationships(p));额外的 collect 语句按以下格式创建列表:
[[rel1, rel2], [rel3, rel4]]
这些列表现在将在映射过程中转换为平面列表。
|
根据要生成的数据量来决定是否选择客户端或数据库端缩减。在使用 |
Using paths to populate and return a list of entities
给定一个如下所示的图形:

以及一个领域模型,如 custom-query.paths.dm 所示(为了简洁,省略了构造函数和访问器):
Unresolved include directive in modules/ROOT/pages/appendix/custom-queries.adoc - include::example$integration/issues/gh2210/SomeEntity.java[]
Unresolved include directive in modules/ROOT/pages/appendix/custom-queries.adoc - include::example$integration/issues/gh2210/SomeRelation.java[]如你所见,关系只是传出的。生成的查找器方法(包括 findById)将始终尝试匹配要映射的根节点。从那里开始,将映射所有相关对象。在应仅返回一个对象的查询中,该根对象将被返回。在返回多个对象的查询中,将返回所有匹配的对象。当然也会填充从这些返回的对象出发的和入发的关系。
假设以下 Cypher 查询:
MATCH p = (leaf:SomeEntity {number: $a})-[:SOME_RELATION_TO*]-(:SomeEntity)
RETURN leaf, collect(nodes(p)), collect(relationships(p))它遵循 Getting one record per root node 的建议,并且对你要在这里匹配的叶子节点非常有用。但是:这仅适用于所有返回 0 个或 1 个映射对象的场景。虽然该查询会像以前一样填充所有关系,但它不会返回全部 4 个对象。
这可以通过返回整个路径来更改:
MATCH p = (leaf:SomeEntity {number: $a})-[:SOME_RELATION_TO*]-(:SomeEntity)
RETURN p在这里,我们确实想要利用这样一个事实,即路径 p 实际上返回 3 行,其中包含指向全部 4 个节点的路径。全部 4 个节点将被填充、链接在一起并返回。
Parameters in custom queries
你执行此操作的方式与在 Neo4j 浏览器或 Cypher-Shell 中发出的标准 Cypher 查询完全相同,语法为 $(从 Neo4j 4.0 开始,数据库中已删除 Cypher 参数的旧 ${foo} 语法)。
Unresolved include directive in modules/ROOT/pages/appendix/custom-queries.adoc - include::example$documentation/repositories/domain_events/ARepository.java[]<1> 在此,我们按名称引用参数。您还可使用 `$0` 等。
|
您需要使用 |
作为参数传递给带有自定义查询注释的函数的映射实体(带 @Node 的所有内容)将变为嵌套映射。以下示例表示 Neo4j 参数的结构。
给定一个如 movie-model 所示使用注释的 Movie、Vertex 和 Actor 类:
@Node
public final class Movie {
@Id
private final String title;
@Property("tagline")
private final String description;
@Relationship(value = "ACTED_IN", direction = Direction.INCOMING)
private final List<Actor> actors;
@Relationship(value = "DIRECTED", direction = Direction.INCOMING)
private final List<Person> directors;
}
@Node
public final class Person {
@Id @GeneratedValue
private final Long id;
private final String name;
private Integer born;
@Relationship("REVIEWED")
private List<Movie> reviewed = new ArrayList<>();
}
@RelationshipProperties
public final class Actor {
@RelationshipId
private final Long id;
@TargetNode
private final Person person;
private final List<String> roles;
}
interface MovieRepository extends Neo4jRepository<Movie, String> {
@Query("MATCH (m:Movie {title: $movie.__id__})\n"
+ "MATCH (m) <- [r:DIRECTED|REVIEWED|ACTED_IN] - (p:Person)\n"
+ "return m, collect(r), collect(p)")
Movie findByMovie(@Param("movie") Movie movie);
}将 Movie 的实例传递给上面的存储库方法将生成以下 Neo4j 映射参数:
{
"movie": {
"__labels__": [
"Movie"
],
"__id__": "The Da Vinci Code",
"__properties__": {
"ACTED_IN": [
{
"__properties__": {
"roles": [
"Sophie Neveu"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 402,
"__properties__": {
"name": "Audrey Tautou",
"born": 1976
}
}
},
{
"__properties__": {
"roles": [
"Sir Leight Teabing"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 401,
"__properties__": {
"name": "Ian McKellen",
"born": 1939
}
}
},
{
"__properties__": {
"roles": [
"Dr. Robert Langdon"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 360,
"__properties__": {
"name": "Tom Hanks",
"born": 1956
}
}
},
{
"__properties__": {
"roles": [
"Silas"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 403,
"__properties__": {
"name": "Paul Bettany",
"born": 1971
}
}
}
],
"DIRECTED": [
{
"__labels__": [
"Person"
],
"__id__": 404,
"__properties__": {
"name": "Ron Howard",
"born": 1954
}
}
],
"tagline": "Break The Codes",
"released": 2006
}
}
}一个节点由一个映射表示。该映射将始终包含 id,它是映射的 ID 属性。在 labels 下将可以使用所有标签(静态和动态)。所有属性以及关系类型都将出现在这些映射中,就像 SDN 编写实体时它们在图形中出现一样。值将具有正确的 Cypher 类型,无需进一步转换。
|
所有关联关系都是地图列表。动态关系将相应地得到解决。一对一关系也将序列化为单例列表。因此,要访问人与人之间的单一对一映射,应该编写此 |
如果一个实体与不同类型的其他节点有相同类型的关系,它们都会出现在同一个列表中。如果你需要这样的映射,并且还需要处理这些自定义参数,则必须相应地展开它。执行此操作的一种方法是使用关联子查询(需要 Neo4j 4.1+)。
Spring Expression Language in custom queries
Spring 表达式语言 (SpEL) 可用于 :#{} 中的自定义查询。这里的冒号指的是一个参数,此类表达式应使用在参数有意义的地方。但是,当使用我们的 literal extension 时,您可以在标准 Cypher 不允许参数(例如对于标签或关系类型)的地方使用 SpEL 表达式。这是定义要进行 SpEL 评估的查询中文本块的标准 Spring Data 方式。
以下示例基本上定义了与上述内容相同的一个查询,但它使用 WHERE 子句来避免使用更多的大括号:
Unresolved include directive in modules/ROOT/pages/appendix/custom-queries.adoc - include::example$documentation/repositories/domain_events/ARepository.java[]SpEL 块以 :#{`开头,然后按名称引用指定的 `String`参数 (#pt1`)。不要将这与上述 Cypher 语法搞混!SpEL 表达式将两个参数串联成一个最终传递给 appendix/neo4j-client.adoc#neo4j-client的单个值。SpEL 块以 `}`结尾。
SpEL 还解决了另外两个问题。我们提供了两个扩展,可将 `Sort`对象传递到自定义查询中。还记得 custom queries中的 faq.adoc#custom-queries-with-page-and-slice-examples吗?通过 `orderBy`扩展,您可以使用动态排序将 `Pageable`传递到自定义查询中:
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
public interface MyPersonRepository extends Neo4jRepository<Person, Long> {
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ ":#{orderBy(#pageable)} SKIP $skip LIMIT $limit" (1)
)
Slice<Person> findSliceByName(String name, Pageable pageable);
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n :#{orderBy(#sort)}" (2)
)
List<Person> findAllByName(String name, Sort sort);
}<1> 在 SpEL 上下文中,`Pageable` 始终名为 `pageable`。 <1> 在 SpEL 上下文中,`Sort` 始终名为 `sort`。
Spring Expression Language extensions
Literal extension
literal 扩展可以用来在自定义查询中使标签或关系类型“动态化”。在 Cypher 中既不能对标签也不能对关系类型进行参数化,因此必须将它们指定为文字。
interface BaseClassRepository extends Neo4jRepository<Inheritance.BaseClass, Long> {
@Query("MATCH (n:`:#{literal(#label)}`) RETURN n") (1)
List<Inheritance.BaseClass> findByLabel(String label);
}<1> `literal` 扩展将替换为已评估参数的字面值。
在此处,literal 值已被用于根据标签动态匹配。如果您将 SomeLabel 作为参数传递到该方法,则会生成 MATCH (n:`SomeLabel) RETURN n`。已添加单引号来对值进行正确的转义。SDN 不会为您执行此操作,因为这可能不是您始终想要的结果。
List extensions
对于多个值,allOf 和 anyOf 可以即时呈现所有值的 & 或 | 连接的列表。
interface BaseClassRepository extends Neo4jRepository<Inheritance.BaseClass, Long> {
@Query("MATCH (n:`:#{allOf(#label)}`) RETURN n")
List<Inheritance.BaseClass> findByLabels(List<String> labels);
@Query("MATCH (n:`:#{anyOf(#label)}`) RETURN n")
List<Inheritance.BaseClass> findByLabels(List<String> labels);
}Referring to Labels
您已经知道如何将节点映射到一个域对象:
@Node(primaryLabel = "Bike", labels = {"Gravel", "Easy Trail"})
public class BikeNode {
@Id String id;
String name;
}此节点带有几个标签,并且在自定义查询中始终重复所有标签非常容易出错:您可能会忘记一个或输入一个错误。我们提供了以下表达式来缓解此问题:#{#staticLabels}。请注意这一选项_不_以冒号开头!它用于具有 @Query 注释的存储库方法:
#{#staticLabels} in actionpublic interface BikeRepository extends Neo4jRepository<Bike, String> {
@Query("MATCH (n:#{#staticLabels}) WHERE n.id = $nameOrId OR n.name = $nameOrId RETURN n")
Optional<Bike> findByNameOrId(@Param("nameOrId") String nameOrId);
}此查询将解析为
MATCH (n:`Bike`:`Gravel`:`Easy Trail`) WHERE n.id = $nameOrId OR n.name = $nameOrId RETURN n请注意我们如何为 nameOrId 使用标准参数:在大多数情况下,无需通过添加 SpEL 表达式来增加这里的复杂性。